TinyEMU源码分析之访存处理
- 1 访存指令介绍
- 2 指令译码
- 3 地址转换
- 3.1 VA与PA
- 3.2 VA转PA
- 4 判断地址空间范围
- 5 执行访存操作
- 5.1 访问RAM内存
- 5.2 访问非RAM(设备)内存
- 6 访存处理流程图
本文属于《 TinyEMU模拟器基础系列教程》之一,欢迎查看其它文章。
1 访存指令介绍
访存指令,主要有,如下这些:


在RISC-V架构中,CPU在处理与内存访问相关的这些指令时,会发出对某地址的访问。这些指令通常涉及加载(Load)和存储(Store)操作,用于从内存中读取数据或将数据写入内存。
本文旨在,通过分析访存指令的执行,以理解CPU在执行指令时,是如何发出以及处理这些地址请求的。
2 指令译码
我们以ld指令(读取)为例,进行说明。
指令形式:
ld rd, imm(rs1)
功能说明:rd = M[rs1+imm][0:63],表示从内存地址(rs1+imm)中,加载一个64位值到寄存器rd
取指译码,是在riscv_cpu_template.h的glue函数中完成,代码如下:
static void no_inline glue(riscv_cpu_interp_x, XLEN)(RISCVCPUState *s,
int n_cycles1)
{
for(;;) {
...
// 取指
insn = get_insn32(code_ptr);
// 译码执行
funct3 = (insn >> 12) & 7;
imm = (int32_t)insn >> 20;
addr = s->reg[rs1] + imm;
switch(funct3) {
...
case 3: /* ld */
{
uint64_t rval;
if (target_read_u64(s, &rval, addr))
goto mmu_exception;
val = (int64_t)rval;
}
break;
}
...
s->reg[rd] = val;
}
}
我们在riscv_cpu.c的target_read_slow函数中,打断点:
b riscv_cpu.c:308 if addr>=0x80000000
再通过调用堆栈,回溯到glue函数中。
当TinyEMU对ld指令,进行译码执行时:
- 从机器码insn中,提取imm;
- 从机器码insn中,提取rs1,并计算出访存地址addr = reg[rs1] + imm。
然后,通过调用target_read_u64函数,读取addr地址内容,放入rd寄存器中。
这里,例子中,各值如下:
- insn == 0xa767b783
- rs1 == 0xf
- imm == 0xfffffa76
- addr == 0x80006d88
这里得到的addr,可能是虚拟地址,也可能是物理地址,我们统一当成虚拟地址看待即可,后续会进行转换。
3 地址转换
3.1 VA与PA
虚拟地址(Virtual Address):
-
处理器生成的地址,用于在软件层面访问内存。虚拟地址空间是程序看到的内存视图,它可能远大于实际的物理内存大小。虚拟地址的主要目的是提供内存保护(通过隔离不同进程的地址空间)和简化内存管理(通过允许操作系统透明地管理物理内存)。
-
在 RISC-V 系统中,虚拟地址通常通过内存管理单元(MMU)进行转换,以映射到物理地址。MMU 负责执行虚拟到物理地址的转换,同时检查访问权限和页面有效性。
物理地址(Physical Address):
-
内存芯片实际使用的地址,用于定位特定的内存位置。物理地址空间是实际可用的 RAM 的大小,它受到硬件和操作系统的限制。
-
在 RISC-V 中,当处理器需要访问内存时,它会生成一个虚拟地址。然后,MMU 会将这个虚拟地址转换为物理地址,处理器使用这个物理地址来访问实际的 RAM。
只有进入OS阶段,开启MMU后,才支持VA;在此之前,所有的访问全都为PA。
3.2 VA转PA
target_read_u64函数,是通过宏来定义的,在riscv_cpu_priv.h中:
#define TARGET_READ_WRITE(size, uint_type, size_log2) \
static inline __exception int target_read_u ## size(RISCVCPUState *s, uint_type *pval, target_ulong addr) \
{\
uint32_t tlb_idx;\
tlb_idx = (addr >> PG_SHIFT) & (TLB_SIZE - 1);\
if (likely(s->tlb_read[tlb_idx].vaddr == (addr & ~(PG_MASK & ~((size / 8) - 1))))) { \
*pval = *(uint_type *)(s->tlb_read[tlb_idx].mem_addend + (uintptr_t)addr);\
} else {\
mem_uint_t val;\
int ret;\
ret = target_read_slow(s, &val, addr, size_log2);\
if (ret)\
return ret;\
*pval = val;\
}\
return 0;\
}\
...
TARGET_READ_WRITE(64, uint64_t, 3)
首先,会查询TLB中,是否有addr(VA)缓存:
- 有的话,直接取出addr对应的PA。
- 没有的话,则调用target_read_slow函数,继续查询。
在target_read_slow函数中,再调用get_phys_addr函数查询。
int target_read_slow(RISCVCPUState *s, mem_uint_t *pval,
target_ulong addr, int size_log2)
{
...
// part1
if (get_phys_addr(s, &paddr, addr, ACCESS_READ)) {
s->pending_tval = addr;
s->pending_exception = CAUSE_LOAD_PAGE_FAULT;
return -1;
}
...
}
如果查询失败,会触发page fault异常,处理器接受到该异常后,会自动创建VA对应的页表。
static int get_phys_addr(RISCVCPUState *s,
target_ulong *ppaddr, target_ulong vaddr,
int access)
{
// 当前是否运行在M模式
if (priv == PRV_M) {
*ppaddr = vaddr;
return 0;
}
// 读取satp寄存器
mode = (s->satp >> 60) & 0xf;
if (mode == 0) {
/* bare: no translation */
*ppaddr = vaddr;
return 0;
} else {
/* sv39/sv48 */
levels = mode - 8 + 3;
pte_size_log2 = 3;
vaddr_shift = MAX_XLEN - (PG_SHIFT + levels * 9);
if ((((target_long)vaddr << vaddr_shift) >> vaddr_shift) != vaddr)
return -1;
pte_addr_bits = 44;
}
// 页表查询
pte_addr = (s->satp & (((target_ulong)1 << pte_addr_bits) - 1)) << PG_SHIFT;
pte_bits = 12 - pte_size_log2;
pte_mask = (1 << pte_bits) - 1;
for(i = 0; i < levels; i++) {
vaddr_shift = PG_SHIFT + pte_bits * (levels - 1 - i);
pte_idx = (vaddr >> vaddr_shift) & pte_mask;
pte_addr += pte_idx << pte_size_log2;
if (pte_size_log2 == 2)
pte = phys_read_u32(s, pte_addr);
else
pte = phys_read_u64(s, pte_addr);
//printf("pte=0x%08" PRIx64 "\n", pte);
if (!(pte & PTE_V_MASK))
return -1; /* invalid PTE */
paddr = (pte >> 10) << PG_SHIFT;
xwr = (pte >> 1) & 7;
if (xwr != 0) {
if (xwr == 2 || xwr == 6)
return -1;
/* priviledge check */
if (priv == PRV_S) {
if ((pte & PTE_U_MASK) && !(s->mstatus & MSTATUS_SUM))
return -1;
} else {
if (!(pte & PTE_U_MASK))
return -1;
}
/* protection check */
/* MXR allows read access to execute-only pages */
if (s->mstatus & MSTATUS_MXR)
xwr |= (xwr >> 2);
if (((xwr >> access) & 1) == 0)
return -1;
need_write = !(pte & PTE_A_MASK) ||
(!(pte & PTE_D_MASK) && access == ACCESS_WRITE);
pte |= PTE_A_MASK;
if (access == ACCESS_WRITE)
pte |= PTE_D_MASK;
if (need_write) {
if (pte_size_log2 == 2)
phys_write_u32(s, pte_addr, pte);
else
phys_write_u64(s, pte_addr, pte);
}
vaddr_mask = ((target_ulong)1 << vaddr_shift) - 1;
*ppaddr = (vaddr & vaddr_mask) | (paddr & ~vaddr_mask);
return 0;
} else {
pte_addr = paddr;
}
}
return -1;
}
这里有2种情况:
- 如果运行在M模式下(运行固件/bios/bootloader),尚未启用MMU时,VA==PA,无需转换。
- 如果运行在S模式下(运行OS),MMU已启用,则读取satp寄存器,并根据该寄存器中,保存的第一级页表基址,进行页表查询,最后得到PA。
具体页表查询原理,我们暂时不关心,只需要理解:
- OS启动过程中,会创建第一级页表,并将其基址保存到satp寄存器,开启MMU。
- 页表,是由OS建立的,保存在物理内存中,我们查询页表,其实就是在遍历内存,以便得到VA对应的PA。
4 判断地址空间范围
int target_read_slow(RISCVCPUState *s, mem_uint_t *pval,
target_ulong addr, int size_log2)
{
...
// part2
pr = get_phys_mem_range(s->mem_map, paddr);
...
}
PhysMemoryRange *get_phys_mem_range(PhysMemoryMap *s, uint64_t paddr)
{
PhysMemoryRange *pr;
int i;
for(i = 0; i < s->n_phys_mem_range; i++) {
pr = &s->phys_mem_range[i];
if (paddr >= pr->addr && paddr < pr->addr + pr->size)
return pr;
}
return NULL;
}
上面转换得到的PA,然后,再调用get_phys_mem_range函数,判断PA到底属于以下地址空间中哪个范围。

也就是说,上面得到的PA地址,可能为0x0~0x88000000范围内的任意地址。
5 执行访存操作
int target_read_slow(RISCVCPUState *s, mem_uint_t *pval,
target_ulong addr, int size_log2)
{
...
// part3
else if (pr->is_ram) {
tlb_idx = (addr >> PG_SHIFT) & (TLB_SIZE - 1);
ptr = pr->phys_mem + (uintptr_t)(paddr - pr->addr);
s->tlb_read[tlb_idx].vaddr = addr & ~PG_MASK;
s->tlb_read[tlb_idx].mem_addend = (uintptr_t)ptr - addr;
switch(size_log2) {
...
case 3:
ret = *(uint64_t *)ptr;
break;
}
} else {
offset = paddr - pr->addr;
if (((pr->devio_flags >> size_log2) & 1) != 0) {
ret = pr->read_func(pr->opaque, offset, size_log2);
}
#if MLEN >= 64
else if ((pr->devio_flags & DEVIO_SIZE32) && size_log2 == 3) {
/* emulate 64 bit access */
ret = pr->read_func(pr->opaque, offset, 2);
ret |= (uint64_t)pr->read_func(pr->opaque, offset + 4, 2) << 32;
}
#endif
}
*pval = ret;
}
这里分为2个分支,看PA是否为RAM地址(Low Dram和High Dram)。
- 访问RAM内存
- 访问非RAM(设备)内存
5.1 访问RAM内存
若PA为RAM地址时,进行以下计算:
ptr = pr->phys_mem + (uintptr_t)(paddr - pr->addr);
(1)计算出欲访问物理地址paddr,相对于RAM物理基址pr->addr的偏移,也就是paddr - pr->addr。
(2)然后,再加上模拟器分配给RAM的内存基址(其实是Host机器的虚拟地址),也就是pr->phys_mem + (uintptr_t)(paddr - pr->addr)。
(3)得到的结果ptr,就是指令欲访问VA,对应的ram内存地址。此时,还会将VA与PA对应关系,更新到TLB中,下次就可以直接查询TLB,而不用查页表了。
最后,通过指针,就可以取出相应长度内容了,通过pval将值返回。
5.2 访问非RAM(设备)内存
若PA为设备地址时,执行以下操作:
- 计算出欲访问物理地址paddr,相对于该设备物理基址pr->addr的偏移,也就是
offset = paddr - pr->addr。 - 然后,调用该设备对应的read_func函数,
ret = pr->read_func(pr->opaque, offset, ...),以便读取该offset处的内容。 - 最后,读取到的值,通过pval返回。
比如CLINT,在riscv_machine_init函数中,划分地址空间时,就将clint_read、clint_write函数指针进行了保存(读写函数、设备地址范围等,进行了捆绑),以便在后续,需要处理该设备地址范围内访问时,可以直接调用该函数。
static VirtMachine *riscv_machine_init(const VirtMachineParams *p)
{
...
// 划分地址空间
cpu_register_device(s->mem_map, CLINT_BASE_ADDR, CLINT_SIZE, s,
clint_read, clint_write, DEVIO_SIZE32);
cpu_register_device(s->mem_map, PLIC_BASE_ADDR, PLIC_SIZE, s,
plic_read, plic_write, DEVIO_SIZE32);
cpu_register_device(s->mem_map, HTIF_BASE_ADDR, 16,
s, htif_read, htif_write, DEVIO_SIZE32);
...
}
比如,PA为0x2004000,写操作的话,那么就是,表示向CLINT中mtimecmp(定时器比较寄存器)写入一个值。mtimecmp是一个内存映射寄存器,定义在CLINT中断控制器中。
clint_write函数定义,如下:
static void clint_write(void *opaque, uint32_t offset, uint32_t val,
int size_log2)
{
...
switch(offset) {
case 0x4000:
m->timecmp = (m->timecmp & ~0xffffffff) | val;
riscv_cpu_reset_mip(m->cpu_state, MIP_MTIP);
break;
...
}
}
此时,计算出的offset为0x4000,然后调用riscv_cpu_reset_mip函数,将val值写入了mip寄存器。
其他的设备,也是类似的原理。
6 访存处理流程图
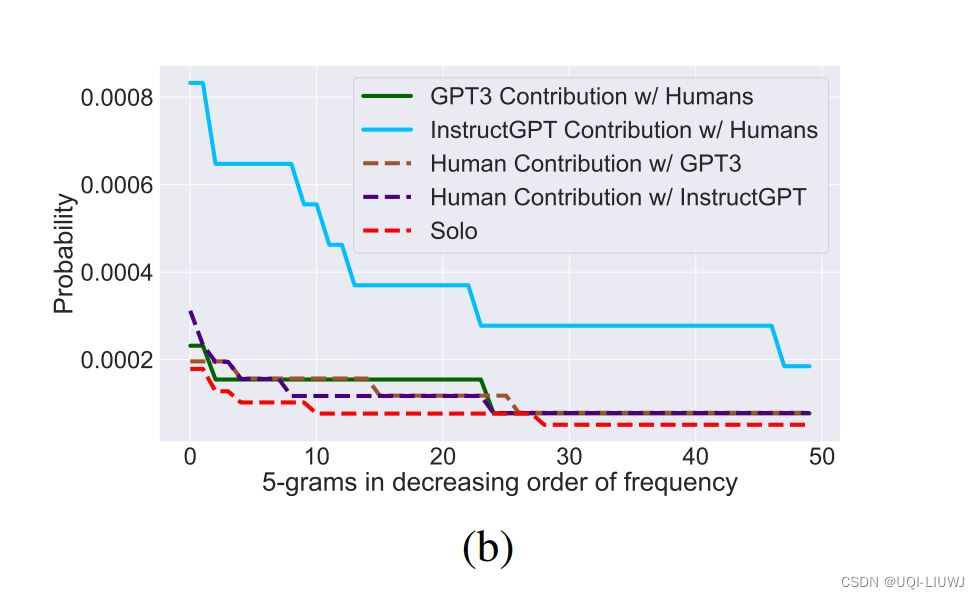
因此,归根到底,CPU在执行指令时,发出的访问地址:
- 如果在RAM范围内,表示访问物理内存;
- 如果在设备范围内,表示访问该设备内部的寄存器或内存资源。
关于访存的处理过程,整理为流程图,如下: